NAS学习笔记(三)FariNAS
引入
FairNAS 的方法是对 NAS 界 One-Shot 派的继承和发扬。One-Shot 派由 Google Brain 创立,主张权重可共享,从头到尾训练一个超网 (只完整训练一个超网,这也是 One-shot 的命名之义),每个模型是超网的一次采样子模型。这样做的好处是不需要将每个模型进行耗时的训练才知道其表征能力,因此以大幅提升 NAS 的效率著称,目前已成为 NAS 的主流。
但 One-Shot 的前提是假定权重共享是有效的,并且模型能力能够通过这种方式快速及准确的验证。要评估模型能力,就好像给一个班的同学考一场试,用明确的考分来决定谁学习不错,谁学习还薄弱一些,虽然不能完全展示每个学生的能力和优势,但总得需要放在同一个尺度上考量。
目前 NAS 评定模型能力的方式,就好比给各个模型一道相同的考题,考的好的就是好模型,不好的就是差模型。但往往有情况是差模型底子并不差,只是训练不得当,所以结果比较差。或者训练不充分,结果比较差。
这种情况就有点像马太效应,家庭条件好的一代比一代强,条件不好的反而陷入循环困境。所以在训练过程中,给予相同的机会和条件来提升其能力是很重要的。这也是小米 AI 实验室 AutoML 团队提出 FairNAS 的核心之处。这一点是被过去的研究有所忽略的。
FairNAS 认为,公平的采样方式和训练方法可以发挥各组成模块的潜能,最终超网训练完成后,采样所得模型可以快速使用超网中的权重在验证集上得到比较稳定的性能指标,这一过程好比一群孩子给予了相同条件的集体培养,多年以后他们显现出的不同就是其真正的天分和努力。这个公平的算法几乎能完全保持模型的排序,从超网采样的模型和单独训练的模型最终有近乎完全一样的排名。
具体来讲,怎么才能保证公平呢?FairNAS 提出了要满足 Strict Fairness,这个约束条件是超网的每单次迭代让每一层可选择运算模块的参数都要得到训练。
从这个定义来看,目前包括 Google 的 One-shot ,MIT 韩松的 Proxyless,旷视的 Single Path One-Shot (SPOS) 都没有满足。从结果来看,Google 的 one-shot 分布域(相当于集体培养后的)比较分散,而 stand-alone 分布域(相当于单独培养的)比较集中,这里的问题是集体培养后表现低,而如果单独培养也并不会很差。所以有可能是培养过程中有所侧重,导致了有些得到了重点培养,而有些被遗忘了。
FairNAS [1] 由小米在 ICCV 2021 上发表,它和 SPOS 非常像,不同的只是将其中的 uniform sampling 改成了公平采样,本文对它做简单的笔记。
1. Fairness
本文主要要解决的问题是训练 child architecture 时产生的 unfairness 的问题,ENAS 和 DARTS 之类的算法都是偏向于初始性能好的 child architecture,在后面的训练中它们更可能被采样,这便是 unfair bias,因此如果 supernet 因为 unfair bias 错误估计了 child architecture 的性能,也就是对 candidate child architecture 的 rank 出现问题时,会大大影响我们的搜索过程,造成 unfairness,难以搜索出真正最优的 child architecture。 作者为了缓解这个问题,提出两种 fairness 的机制,Expectation Fairness 和 Strict Fairness。 FairNas 的 supernet 结构和 SPOS 是类似的,都是 single path,每层里采样一个 choice block,我们定义训练过程为 \(P(m, n, L)\),其中 m 指的每层里 choice block 的个数,n 指的是 weights 被更新的次数,L 指的是 supernet 的层数。
1.1 Expectation Fairness
顾名思义,Expectation Fairness 要保证的就是,所有的 m 种 choice block 在更新 n次后都能有相同的期望,它的定义如下:

SPOS 中采用的 uniform sampling 是满足这个约束的,且:
\[\begin{aligned} E\left(Y_{l_i}\right) & =n * p_{l_i}=n / m \\ \operatorname{Var}\left(Y_{l_i}\right) & =n * p_{l_i}\left(1-p_{l_i}\right)=\frac{n(m-1)}{m^2} \end{aligned}\]
- \(\Omega\) 为采样空间
但即使如此,SPOS 中也存在 unfairness,它主要是一个 order issue,即如果我们在训练 supernet 时采样了一组 architecture \({M1,M2,M3}\) ,训练 M2 的时候,已经用到了受到了训练完 M1 造成的影响了,并且如果学习率还不同的话,会产生更复杂的情况。 这里作者还指出了一个反逻辑的事实,也就是 n 趋近无穷时时,每个 choice block 的采样数不可能一样,数学化就是:
\[Regarding P(m, n, L), \forall n \in\left\{x: x \% m=0, x \in N_{+}\right\},\\ \lim _{n \rightarrow+\infty} p\left(Y_{l 1}=Y_{l 2}=\ldots=Y_{l m}\right)=0\]
证明如下:

1.2 Strict Fairness
针对 Expectation Fairness 的问题,作者提出了 Strict Fairness:
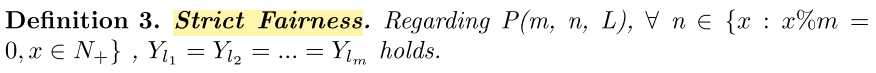
2. FairNAS
FairNas 和 SPOS 一样,也是一个 two-stage 的 One-Shot 算法,第一个 stage 训练 train supernet,第二个 stage 搜索最优的 architecture。
2.1 Train Supernet with Strict Fairness
FairNAS 是支持 Strict Fairness 的,它实际上是在 uniform sampling 的基础上加了一个公平采样,就是每次 update weights 时同时采样出 m 个 architecture,并且是不放回的,所以每层的每个 choice block 都有被采样的机会,然后分别训练这 m 个 architecture,然后分别做 BP,将梯度累加起来在 supernet 中做一次 update weights,论文中称这个为一次 supernet step,论文中的图把这个思想解释的很清楚:
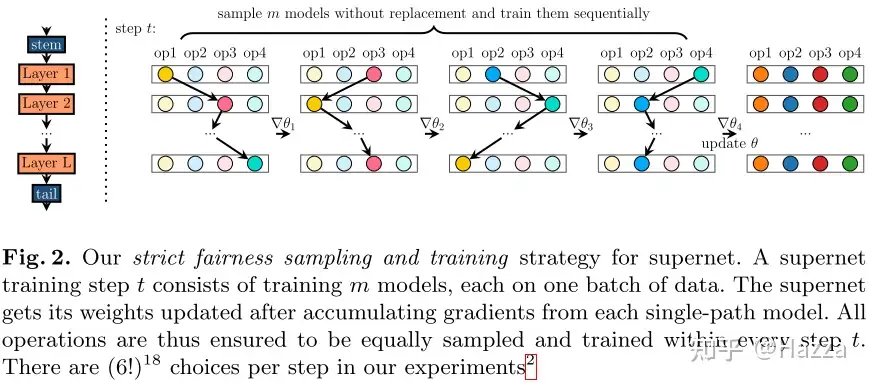
方差相比 uniform sampling 来说还减小了。伪代码如下:

2.2 Searching with Supernet as an Evaluator
搜索的过程依然使用了 evolutionary algorithm:

Url
论文链接:PaperWeekly
源码链接:fairnas/FairNAS