NAS学习笔记(一)GreedyNAS
引言
商汤在 CVPR 2020 上提出了 GreedyNAS,它也是一种 One-Shot NAS,优点是对 supernet 做了贪心操作,本文对它做简单的笔记。
1. Motivation
我们知道在 One-Shot 模型里,supernet 的训练质量是至关重要的,因为在搜索的时候采样的 child architecture 不会再训练,直接 infer。我们之前介绍过的 Single Path One-Shot 和 FairNAS 方法都是尽可能的想让 sueprnet 训练时对每个采样都公平点,将 supernet 中每一个 architecture 认为 是同等重要的,supernet 应该对每个结构进行准确评估或相对排序。然而 supernet中所包含的搜索空间的是非常巨大的,想要准确的评估对于 supernet 来说是非常困难的,会导致 supernet 中结构的表现与其真实表现相关性很差,要求 supernet 正确预测所有路径准确率过于严苛。并且由于训练超网过程中所有路径高度共享,训练不好的路径可能对好的路径造成干扰。 因此 GreedyNAS 试图解决这些问题,主要思路就是使用多路径采样策略过滤不好的路径,使 supernet 训练更加聚焦潜在优异的路径。
2. Greedy path filtering
作者将 supernet 的搜索空间作如下定义:
\[\mathcal{A}=\mathcal{A}_{\text {good }} \bigcup \mathcal{A}_{\text {weak }}, \mathcal{A}_{\text {good }} \bigcap \mathcal{A}_{\text {weak }}=\emptyset\]

2.1 Multi-path sampling with rejection
我们的目标就是在训练 supernet 时从 \(\mathcal{A}good\) 采样 path,即:
\[p\left(\boldsymbol{a} ; \mathcal{N}_o, \mathcal{D}_{\text {val }}\right)=\frac{1}{\left|\mathcal{A}_{\text {good }}\right|} \mathbb{I}\left(\boldsymbol{a} \in \mathcal{A}_{\text {good }}\right)\]
但是因为 supernet 是未知的,我们很难分出 \(\mathcal{A}good\)和 \(\mathcal{A}weak\) ,遍历搜索空间一遍开销肯定是不能接受的,所以作者提出了一种多路径拒绝式采样方法。
我们定义 \(q=|\mathcal{A}_{good}|/|\mathcal{A}|\) ,则从 $_{weak} \(的概率就是\) 1−q $,那么假设我们采样 \(m\) 个 path,则至少有 \(k\) 个 path 来自 \(\mathcal{A}_{good}\)的概率就是:\(\sum_{j=k}^m \mathbb{C}_m^j q^j(1-q)^{m-j}\)
当 \(q\)较大或者\(k\) 较小时这个概率都是很大的,所以作者每次就简单的挑选 \(top- k\) 的 path 去训练。
因为挑选 top- \(k\) 又涉及到了在\(\mathcal{D}_{val}\) 上训练得到 ACC 去排序,这个操作也是开销比较大的,因次作者仅使用 \(\mathcal{D}_{val}\)的一个子集 来训练得到 loss 去做排序,整个过程的伪代码如下:

3. Greedy training of supernet
3.1 Training with exploration and exploitation
因为我们每次做完 greedy path filtering 后得到一些可能比较好的 path,它们一次训练可能不够充分,有重复训练的必要,所以这里作者也提出了一个 exploration 和 exploitation 的 trade-off,即使用一个 candidate pool\(\mathcal{P}\) 来存储这些比较好的 path,并且它其实是一个优先队列,priority 是每个 path 做 evaluation 时的 loss,下次训练时采取如下的采样:
\[\boldsymbol{a} \sim(1-\epsilon) \cdot U(\mathcal{A})+\epsilon \cdot U(\mathcal{P})\]
因为 supernet 在训练初期是训练不充分的,每个 path 得到的 loss 不可信,也就是 priority 不可信,所以作者将 \(\epsilon\)从 0 开始逐渐升大
3.2 Stopping principle via candidate pool Different
作者采取一种自适应的条件来终止训练,主要依据 candidate pool 的大小有没有稳定了.
3.3 Searching with candidate pool
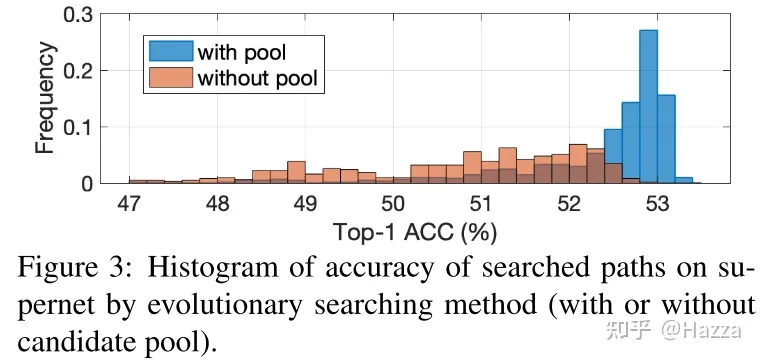
supernet 训练完毕后,使用 NSGA-II 进化算法在超网中搜索符合条件的最优模型,并且使用 candidate pool 初始化 Population,相较于随机初始化,借助于候选池能够使进化算法有一个更好的初始,提升搜索效率及最终的精度能得到更好的模型分布:
4 实验部分
4.1 Imagenet
- 相同搜索空间
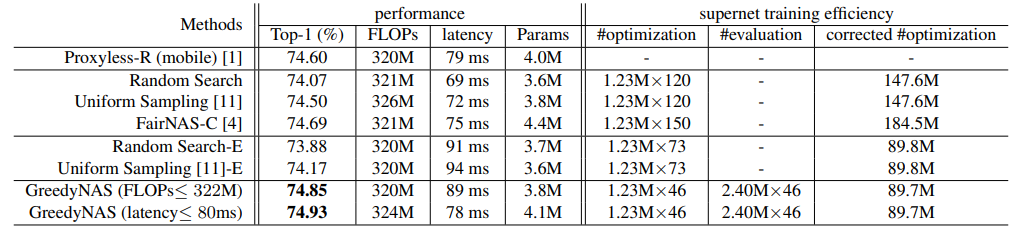
在相同搜索空间下,不同搜索方法在ImageNet数据集上的分类性能和超网络训练效率比较。#optimization为整步优化计算的累计#例数,#evaluation为前向求值。#corrected是基于我们的统计数据,整个优化步骤的成本是正向评估的3.33倍。
- 增强搜索空间

在三种不同的搜索空间上进行了搜索。
4.2 消融实验
- 小验证集和大验证集的相关度
为了过滤弱路径,GreedyNAS通过一小部分(1000)验证图像作为整个验证数据集(50K图像)的代理来评估每个路径。首先研究这个近似在我们的实验中是否足够。通过从supernet随机采样1000条路径,检查了两种路径排序的相关性,这两种路径排序分别是通过使用1000和50K验证图像对评估结果进行排序生成的。在表3中报告了广泛使用的Spearman rho[25]和Kendall tau[13]秩相关系数,它们的范围为[0,1],值越大表示相关性越强。我们还讨论了三种类型的超网络,即随机初始化、均匀抽样训练和我们的贪婪抽样。从表3可以看出,我们的贪心超网络获得了相当高的秩相关系数(0.997和0.961),表明1000张验证图像对贪婪超网络的排序与所有验证数据集的排序显著一致。而且,均匀采样训练的超网络,即使是不同的评价图像,相关系数也较小(见左)

各个模块使用对网络的影响
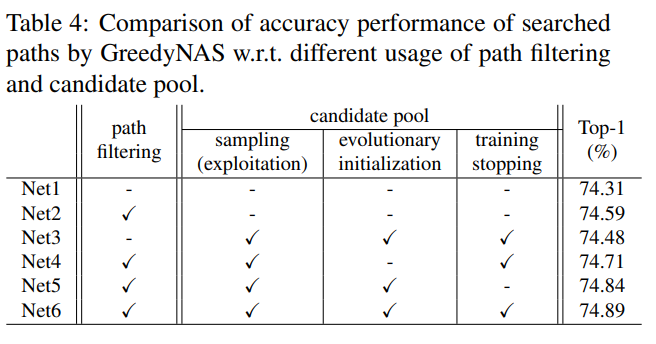
影响确实不是很大。
总结
商汤的这篇论文解决的核心问题就是让 supernet 更注重于有潜力的好 path 的训练,并且使用了贪心算法,提出了 multi-path sampling with rejection 和 candidate pool 的方法,还是非常让人有启发的。